
Depending On The Model: Strategies For Reliable AI
As someone who has built, deployed, and monitored machine learning systems across fintech, e-commerce, and healthcare, I’ve seen how depending on the model can be a competitive advantage—or a fast track to failure. In this guide, I’ll unpack what depending on the model really means, why it matters, and how to do it responsibly. If your product, workflow, or business decision relies on an AI model, this article offers a practical roadmap to reduce risk, improve performance, and build trust. Let’s dive in with real examples, research-backed insights, and hard-won lessons from the field.
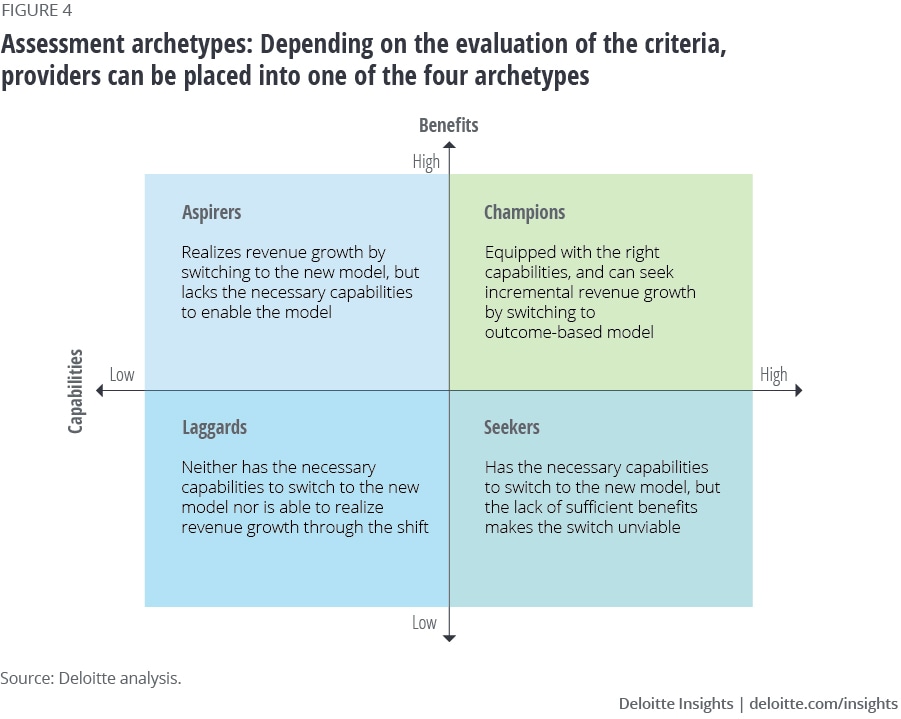
Source: www.deloitte.com
What Does “Depending On The Model” Really Mean?
Depending on the model describes how much a system’s outcomes hinge on the predictions, generations, or classifications made by machine learning models. It spans technical, operational, and business dependencies.
Key dimensions:
- Decision criticality: Is the model a convenience feature or mission-critical for revenue, safety, or compliance?
- Autonomy: Are outputs used directly, or is there human review in the loop?
- Substitutability: Can a rule-based fallback or heuristic stand in if the model fails?
- Traceability: Can you explain why the model made a decision and reproduce it?
- Change tolerance: How sensitive is the system to model updates, drift, or vendor changes?
When teams don’t define these dimensions, they unconsciously overfit their business to the model. Done well, model dependency becomes a managed asset.

Source: medicalmonks.com
When Dependence Is An Asset, Not A Liability
Strategic dependence on AI models can unlock:
– Speed and scale: Automating decisions that humans can’t do in real time, like fraud detection at checkout.
– Personalization lift: Tailoring content, pricing, and UX to users, improving conversion and retention.
– Cost efficiency: Reducing manual effort in support, triage, and document processing.
– Competitive differentiation: Proprietary data and fine-tuned models create durable advantage.
Personal insight: In an e-commerce project, we moved from rules to a ranking model for search. Conversion rose 7%, and long-tail products finally surfaced. The key was coupling the model with guardrails and experimentation rather than treating it as a black box.

Source: www.researchgate.net
Risks Of Over-Dependence You Shouldn’t Ignore
Model dependence introduces risk at multiple layers:
– Data drift and concept drift: Input distributions change, and the real-world meaning of labels evolves.
– Feedback loops: Model outputs influence future inputs, potentially amplifying bias.
– Hidden coupling: Upstream schema changes break downstream models without obvious errors.
– Vendor lock-in: Proprietary models or embeddings make switching costly.
– Compliance and ethics: Regulations like the EU AI Act and industry standards require documentation, explainability, and risk controls.
Mistake to avoid: Relying only on offline accuracy. Operational metrics such as calibration, stability, and decision quality in production matter more than leaderboard scores.
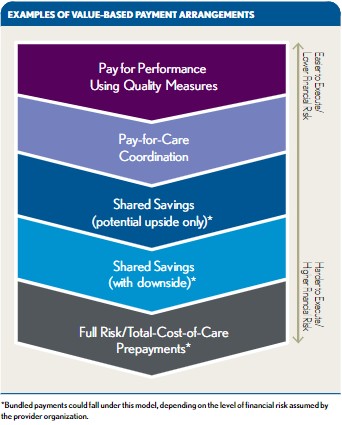
Source: www.hfma.org
Evaluating Model Readiness Before You Depend On It
Use a readiness checklist to decide if your system should depend on the model:
– Performance: Beyond accuracy—measure AUROC, AUPRC, calibration error, cost-sensitive metrics, and fairness slices.
– Robustness: Test against noisy inputs, adversarial prompts, and out-of-distribution data.
– Explainability: Provide feature attributions, rationales, and uncertainty estimates suitable for the audience.
– Reproducibility: Version data, code, and model weights with immutable lineage.
– Safety: Define harmful failure modes and red-team the system.
– Human factors: Determine when human review is mandatory and how to design escalations.
Practical example: A healthcare triage model passed offline metrics but failed in busy clinics due to latency and ambiguous explanations. Adding confidence thresholds and clinician tooltips made the system usable and safe.
Data Quality And Drift: The Quiet Drivers Of Dependency Risk
Your model is only as dependable as the data lifecycle behind it:
– Governance: Establish owners for datasets, schemas, and SLAs for refresh cadence.
– Validation: Enforce contracts for features and labels; catch nulls, ranges, and unit mismatches early.
– Drift detection: Monitor population stability, PSI/JS divergence, and label shift indicators.
– Retraining policy: Trigger retraining based on drift thresholds, not fixed calendars.
– Feedback loops: Capture human corrections to improve labels and close the loop.
Evidence-based note: Studies consistently show that production error is dominated by data issues rather than model architecture. Invest accordingly.
Human-In-The-Loop And Governance That Scales
Strong governance reduces risky dependence:
– Risk tiers: Classify use cases as minimal, limited, or high risk, with escalating controls.
– Human-in-the-loop: Introduce review for low-confidence cases, sensitive segments, or high-cost errors.
– Documentation: Maintain model cards, data sheets, and change logs for audits and trust-building.
– Ethics and fairness: Define impact assessments, sensitive attributes, and mitigation strategies.
– Incident response: Treat model failures like outages with runbooks, on-call, and postmortems.
Personal tip: Our team cut false positives in content moderation by 30% after implementing tiered review and a simple appeal workflow.
Architecture Patterns To Reduce Fragile Model Dependence
Design your systems to degrade gracefully:
– Sandwich pattern: Rules or constraints before and after the model to sanitize inputs and audit outputs.
– Shadow mode: Run models in parallel without affecting users until metrics stabilize.
– Champion-challenger: Continuously test challengers against the current champion to avoid regressions.
– Fallbacks: Provide deterministic heuristics or cached responses when models fail or exceed latency budgets.
– Abstractions: Use adapters and feature stores to decouple upstream data and downstream consumers.
– Multi-model ensembles: Blend diverse models to reduce variance and improve resilience.
Implementation lesson: A simple heuristic fallback preserved 85% of search quality during a provider outage, preventing a costly incident.
Monitoring, SLAs, And Operational Excellence
You can’t depend on what you don’t monitor:
– Metrics to track: Latency, throughput, error rate, cost per request, acceptance rate, drift, calibration, and fairness slices.
– Quality evaluation: Periodic human ratings and golden sets for generative outputs.
– Alerts and SLOs: Define user-centric SLOs and page on meaningful breaches, not noise.
– Observability: Log prompts, features, and decisions with privacy-safe redaction and trace IDs.
– Cost controls: Monitor token usage, GPU time, and storage to keep unit economics healthy.
Pro tip: Set budgets and automated throttles for unexpected traffic spikes to avoid surprise cloud bills.
Cost, Latency, And Accuracy: Making The Right Trade-offs
Depending on the model means balancing constraints:
– Latency budgets: Users feel delays over roughly 200–500 ms for interactive flows.
– Accuracy vs. coverage: High confidence thresholds may reduce recall; decide what matters more in context.
– Cost per decision: Use smaller or distilled models for non-critical paths, reserving premium models for high-value cases.
– Personalization depth: More features can improve accuracy but increase privacy and complexity risks.
Practical approach:
- Tier your workloads by value.
- Route requests based on confidence and complexity.
- Cache frequent results and apply time-to-live strategies.
Real-World Stories: Wins, Missteps, And Lessons
– The silent schema shift: A partner changed a currency field from integer cents to decimal units. Our fraud model over-flagged transactions. Lesson: enforce schema validation and unit tests at ingestion.
– The hero model that drifted: Seasonal demand changed user behavior. Performance fell 12% before detection. Lesson: set drift monitors and calendar-aware retraining windows.
– The explainability unlock: Adding counterfactual explanations in credit decisions improved approval rates while satisfying compliance. Lesson: explanations aren’t just for audits—they drive better user and reviewer decisions.
– The cost cliff: Prompt expansion in a genAI assistant doubled token usage. Lesson: treat prompts, context windows, and sampling parameters as budgeted assets.
These small operational choices determine whether depending on the model boosts trust or erodes it.
A Practical Implementation Checklist
Use this checklist to make dependence intentional and safe:
– Define decision criticality, risk tier, and acceptable failure modes.
– Choose metrics beyond accuracy: calibration, cost-weighted utility, and fairness slices.
– Build guardrails: input validation, content filters, and policy checks.
– Establish drift monitoring, alerting, and retraining triggers.
– Implement human-in-the-loop for ambiguous or high-impact cases.
– Document with model cards, data lineage, and change logs.
– Architect for resilience: fallbacks, shadowing, and champion-challenger.
– Set SLOs and budgets for latency, reliability, and cost.
– Plan incident response and run regular fire drills.
– Review ethics, privacy, and regulatory obligations early.
If you adopt even half of these, you’ll depend on the model confidently rather than crossing your fingers.
Frequently Asked Questions Of Depending On The Model
What Does “Depending On The Model” Mean In Practice?
It means your product or process outcomes rely on model outputs. The degree of dependence involves decision criticality, human oversight, fallback options, and how tightly your architecture couples to the model.
How Do I Know If It’s Safe To Depend On A Model?
Check readiness across accuracy, calibration, robustness, explainability, and operational monitoring. If you have clear guardrails, drift alerts, and human review where needed, you’re closer to safe dependence.
What Metrics Matter Most Beyond Accuracy?
Calibration error, cost-sensitive utility, stability over time, fairness across key segments, and latency. For generative systems, add human rating quality, toxicity, and factuality checks.
How Do I Handle Model Drift?
Monitor input and label distributions, set thresholds for alerts, and retrain based on data shifts or performance decay. Keep a rolling evaluation set and validate before promotion.
How Can I Reduce Vendor Lock-In?
Abstract model interfaces, store embeddings in open formats, maintain prompt templates separately, and test portable open-source alternatives so switching is feasible.
When Should I Use Human-In-The-Loop?
Use it for high-risk decisions, low-confidence outputs, and cases with high cost of error. Over time, shrink the review surface as model confidence and monitoring mature.
What Are Good Fallback Strategies?
Deterministic rules, cached responses, smaller local models for outages, and deferring to human review when uncertainty exceeds a threshold.
Conclusion
Depending on the model doesn’t have to be a leap of faith. With the right metrics, governance, architecture, and monitoring, model dependence becomes a strategic advantage rather than a liability. Start small, add guardrails, measure what matters, and iterate with intention. Your future self—and your users—will thank you.
Ready to make smarter, safer bets on AI? Put the checklist into action this week, subscribe for more practical guides, and share your lessons in the comments.





